
Kicking off with Amazon Redshift tutorial, this comprehensive guide explores the ins and outs of data warehousing and analytics, providing valuable insights for both beginners and experienced users alike.
From setting up clusters to querying data, this tutorial covers everything you need to know about Amazon Redshift.
Introduction to Amazon Redshift
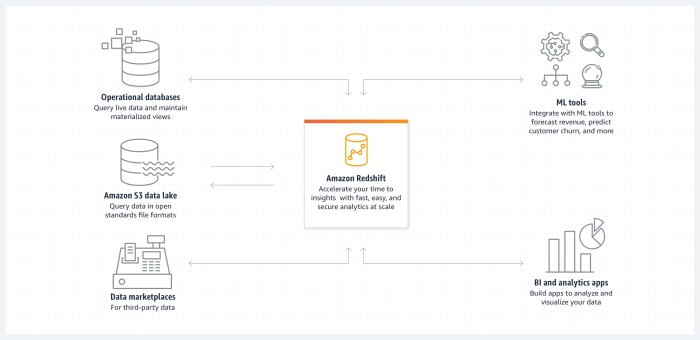
Amazon Redshift is a fully managed, petabyte-scale data warehouse service provided by Amazon Web Services (AWS). It is designed to handle large datasets and perform complex queries to help businesses analyze their data effectively.
One of the key purposes of Amazon Redshift is to enable organizations to store and analyze vast amounts of data in a cost-effective and efficient manner. This cloud-based data warehousing solution allows users to scale their storage and compute resources as needed, making it ideal for businesses of all sizes.
Benefits of Using Amazon Redshift
- Scalability: Amazon Redshift can easily scale to accommodate growing data volumes without compromising performance.
- Performance: It offers fast query processing and high-performance analytics, allowing users to derive insights from their data quickly.
- Cost-effective: With a pay-as-you-go pricing model, users only pay for the resources they use, making it a cost-effective solution for data warehousing.
- Integration with other AWS services: Amazon Redshift seamlessly integrates with other AWS services, such as S3 and EMR, enhancing its capabilities.
Key Features of Amazon Redshift
- Columnar storage: Amazon Redshift stores data in a columnar format, which improves query performance and reduces storage costs.
- Distributed architecture: It uses a massively parallel processing (MPP) architecture to distribute queries across multiple nodes, enabling parallel processing of data.
- Advanced compression: Amazon Redshift uses advanced compression techniques to reduce the amount of storage needed, optimizing query performance.
- Data encryption: It provides strong encryption mechanisms to ensure data security and compliance with industry standards.
Setting up Amazon Redshift: Amazon Redshift Tutorial

To get started with Amazon Redshift, you’ll need to set up a Redshift cluster, choose the appropriate node type, and configure security settings. Below is a step-by-step guide on how to accomplish these tasks.
Creating an Amazon Redshift Cluster, Amazon Redshift tutorial
To create an Amazon Redshift cluster, follow these steps:
- Sign in to the AWS Management Console and open the Amazon Redshift console.
- Click on “Clusters” and then “Create cluster” to start the cluster creation wizard.
- Specify the cluster details such as node type, number of nodes, and cluster identifier.
- Configure the database details, including the database name, port, and master user credentials.
- Set up additional configurations like VPC, security groups, and encryption settings.
- Review your configuration and click “Create cluster” to provision your Amazon Redshift cluster.
Node Types in Amazon Redshift
Amazon Redshift offers different node types to meet various performance and scalability needs. Here are some common node types and their use cases:
“dc2.large”: Suitable for smaller workloads and testing purposes.
“ds2.xlarge”: Balanced compute and storage for medium-sized workloads.
“dc2.8xlarge”: High-performance compute nodes for large-scale data processing.
“ra3.xlplus”: Designed for high-performance workloads with managed storage.
Configuring Security Settings for Amazon Redshift
To ensure the security of your Amazon Redshift cluster, consider implementing the following security settings:
- Enable encryption at rest to protect your data stored in the cluster.
- Set up IAM roles and policies to control access to your Redshift cluster.
- Create user accounts with appropriate permissions and access levels.
- Implement network security by configuring VPC routing and security groups.
- Regularly monitor and audit your cluster for any security vulnerabilities or unauthorized access.
Data Loading in Amazon Redshift

Data loading in Amazon Redshift is a crucial step in utilizing the power of this data warehouse service. It involves transferring data from various sources into Redshift for analysis and querying. There are several methods and best practices that can help optimize data loading performance and ensure efficiency in handling large datasets.
Methods for Loading Data into Amazon Redshift
- Using COPY command: The most common method for loading data into Redshift is through the COPY command. This command allows you to bulk load data from Amazon S3, Amazon DynamoDB, or other sources directly into Redshift tables.
- Data migration tools: Amazon Redshift is compatible with various data migration tools like AWS Database Migration Service (DMS) and AWS Glue, which can help streamline the process of transferring data into Redshift.
Best Practices for Optimizing Data Loading Performance
- Use optimal file formats: Choose the best file format for your data, such as Parquet or ORC, to improve data loading performance.
- Distribute data evenly: Distribute data evenly across nodes to avoid data skew and improve query performance.
- Monitor and optimize data loading: Regularly monitor data loading processes and optimize performance by fine-tuning parameters like SORTKEY and DISTKEY.
Common Data Loading Scenarios in Amazon Redshift
- Loading large datasets: For large datasets, consider using the COPY command with options like COMPUPDATE and STATUPDATE to optimize data loading performance.
- Incremental data loading: When loading incremental data, use tools like AWS Glue or AWS Data Pipeline to automate the process and ensure data consistency.
- Data transformations: Perform data transformations during the loading process using SQL scripts or AWS Glue to prepare data for analysis in Redshift.
Querying Data in Amazon Redshift

When working with Amazon Redshift, querying data is a crucial aspect of data analysis. SQL queries play a vital role in extracting insights and information from your database. In this section, we will explore how to write SQL queries in Amazon Redshift, optimize query performance, and efficiently retrieve data.
Writing SQL Queries in Amazon Redshift
Writing SQL queries in Amazon Redshift follows standard SQL syntax, but there are some specific functions and features that are unique to Amazon Redshift. To write effective queries, consider the following tips:
- Use EXPLAIN to analyze query plans and optimize performance.
- Utilize distribution keys and sort keys to improve query performance.
- Minimize data movement by using subqueries and joins efficiently.
Performance Tuning Techniques
Optimizing query execution in Amazon Redshift is essential for efficient data analysis. Consider the following performance tuning techniques:
- Use appropriate data types to reduce storage and improve query speed.
- Analyze query execution times and identify bottlenecks for optimization.
- Implement compression to reduce storage costs and improve query performance.
Examples of Complex Queries
Complex queries are common in data analysis, and Amazon Redshift can handle intricate queries efficiently. Here are some examples of complex queries and how to retrieve data efficiently:
- Aggregating data from multiple tables using JOIN and GROUP BY clauses.
- Using window functions for advanced analytics and calculations.
- Optimizing queries with filters, indexes, and proper data modeling.
In conclusion, Amazon Redshift tutorial offers a powerful solution for data analytics, revolutionizing the way businesses handle their data. Dive into the world of Amazon Redshift and unlock its full potential for your data needs.