
Data mining vs machine learning sets the stage for this enthralling narrative, offering readers a glimpse into a story that is rich in detail and brimming with originality from the outset. As we delve into the realms of data analysis, the distinctions between these two powerful tools become clearer, paving the way for a deeper understanding of their unique roles and applications.
Definition of Data Mining and Machine Learning

Data mining involves the process of discovering patterns, trends, and insights from large datasets using various techniques such as machine learning, statistical analysis, and artificial intelligence. The primary objective of data mining is to extract valuable information that can be used for decision-making and predictive modeling.
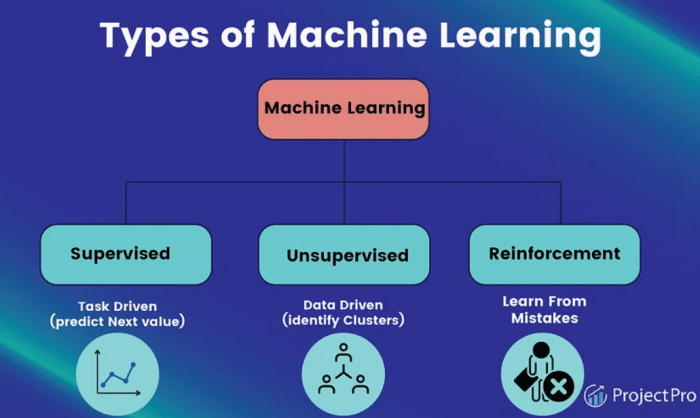
Machine learning, on the other hand, is a subset of artificial intelligence that focuses on developing algorithms and models that enable computers to learn from data and make predictions or decisions without being explicitly programmed. Key concepts in machine learning include supervised learning, unsupervised learning, and reinforcement learning.
Differentiation between Data Mining and Machine Learning
- Data mining is the process of extracting useful patterns and insights from large datasets, while machine learning focuses on developing algorithms that can learn from data and make predictions.
- Data mining involves techniques such as clustering, classification, and regression to analyze data, whereas machine learning algorithms include decision trees, neural networks, and support vector machines.
- While data mining is more focused on discovering hidden patterns in data, machine learning is geared towards developing predictive models and making data-driven decisions.
Examples of Data Mining and Machine Learning Applications
- Data Mining: Retail companies use data mining to analyze customer purchase patterns and preferences to optimize marketing strategies. Healthcare organizations utilize data mining to identify trends in patient outcomes and improve treatment protocols.
- Machine Learning: Recommendation systems on streaming platforms like Netflix use machine learning algorithms to suggest movies or TV shows based on user preferences. Fraud detection systems in banking use machine learning to identify suspicious transactions and prevent fraudulent activities.
Techniques and Algorithms
Data mining and machine learning utilize various techniques and algorithms to extract valuable insights from data. While they share some similarities, they also have distinct approaches when it comes to analyzing and processing data.
Common Techniques in Data Mining:
- Association Rule Mining: This technique is used to discover interesting relationships between variables in large datasets. One popular algorithm for association rule mining is the Apriori algorithm.
- Clustering: Clustering techniques group similar data points together based on certain characteristics. K-means clustering is a widely used algorithm in this field.
- Classification: Classification techniques categorize data into predefined classes or labels. Decision trees and Support Vector Machines (SVM) are commonly used algorithms for classification tasks.
Popular Algorithms in Machine Learning:
- Linear Regression: This algorithm is used to establish a linear relationship between input and output variables. It is commonly employed in predictive modeling.
- Random Forest: Random Forest is an ensemble learning method that builds multiple decision trees to improve prediction accuracy and reduce overfitting.
- Deep Learning: Deep learning algorithms, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), are used for complex pattern recognition tasks like image and speech recognition.
Differences in Techniques and Algorithms:
Data mining focuses on extracting patterns and insights from large datasets, often with a focus on identifying hidden relationships. Machine learning, on the other hand, emphasizes building predictive models and making decisions based on data patterns.
When it comes to making data-driven decisions in business, data visualization plays a crucial role. By presenting complex data in a visual format, businesses can easily identify patterns, trends, and outliers, leading to more informed strategies and actions.
Real-World Examples:
One real-world example of data mining is customer segmentation in e-commerce, where clustering techniques are used to group customers based on their purchasing behavior. In machine learning, a common example is the use of recommendation systems in streaming platforms like Netflix, which employ collaborative filtering algorithms to suggest content based on user preferences.
Data Sources and Preprocessing

When it comes to data mining and machine learning, the quality of data sources and the preprocessing steps play a crucial role in the success of the analysis and predictions. In this section, we will delve into the types of data sources used in data mining, discuss data preprocessing steps in machine learning, compare the data sources and preprocessing methods in data mining versus machine learning, and illustrate how data quality impacts the outcomes in both fields.
Types of Data Sources
In data mining, the types of data sources can vary widely and may include databases, data warehouses, text files, XML, CSV files, and more. These sources can be structured, semi-structured, or unstructured data that are collected from various systems and applications.
Data Preprocessing in Machine Learning
Data preprocessing is a crucial step in machine learning that involves cleaning, transforming, and organizing raw data before feeding it into a machine learning algorithm. This step includes handling missing values, dealing with outliers, standardizing the data, encoding categorical variables, and splitting the data into training and testing sets.
Comparison of Data Sources and Preprocessing Methods
In data mining, the focus is on extracting patterns and insights from large datasets, which may require specialized tools and techniques to handle the volume and variety of data sources. On the other hand, machine learning algorithms rely on clean and well-preprocessed data to make accurate predictions and classifications.
While data mining may involve more complex data preprocessing steps due to the nature of the data sources, machine learning algorithms are more sensitive to the quality and consistency of the data. Data preprocessing in machine learning aims to ensure that the data is in a format that the algorithms can effectively learn from, leading to more accurate results.
Impact of Data Quality, Data mining vs machine learning
Data quality is paramount in both data mining and machine learning, as the accuracy and reliability of the results heavily depend on the quality of the data used. Poor data quality can lead to biased models, inaccurate predictions, and unreliable insights. Therefore, data preprocessing steps such as data cleaning, normalization, and feature engineering are essential to improve the quality of the data and enhance the performance of the algorithms.
Supervision and Automation: Data Mining Vs Machine Learning

When it comes to data mining and machine learning, the concepts of supervision and automation play crucial roles in determining the efficiency and effectiveness of the processes involved.
Supervision in Machine Learning
In machine learning, supervision refers to the process of providing labeled training data to the algorithm. This labeled data allows the algorithm to learn from examples and make predictions or decisions based on the patterns it identifies. Supervised learning algorithms are trained using input-output pairs, where the algorithm learns to map input data to the correct output.
- Examples of supervised learning in machine learning include classification tasks, where the algorithm learns to classify new data points into predefined categories based on the training data it has been provided.
- Another example is regression analysis, where the algorithm learns to predict continuous numerical values based on the input data and the relationships it identifies.
Automation in Data Mining
Automation in data mining involves the use of algorithms and tools to automatically extract patterns, trends, and insights from large datasets without the need for manual intervention. Automated data mining processes help organizations streamline their data analysis workflows and make informed decisions based on the insights generated.
- Automated processes in data mining include techniques such as clustering, association rule mining, and anomaly detection, where algorithms are used to identify patterns and relationships in the data without human involvement.
- Tools like RapidMiner, KNIME, and Weka are examples of platforms that offer automation capabilities for data mining tasks, allowing users to preprocess, analyze, and visualize data efficiently.
In conclusion, the comparison between data mining and machine learning sheds light on the diverse approaches to extracting valuable insights from data. By grasping the nuances of each technique, businesses and researchers alike can leverage the power of these tools to drive innovation and make informed decisions in the ever-evolving landscape of data analytics.
Understanding the differences between data warehousing and databases is essential for managing and analyzing large volumes of data effectively. While databases are designed for transactional processing, data warehouses are optimized for analytical queries and reporting.
Choosing between a database, data lake, or data warehouse depends on the specific needs of your organization. While databases are ideal for structured data, data lakes can handle unstructured data, and data warehouses are best for storing and analyzing historical data.