
Predictive analytics with machine learning is a cutting-edge approach that revolutionizes the way businesses harness data to predict future outcomes and trends. This comprehensive guide explores the fusion of predictive analytics and machine learning, offering a deep dive into its applications, algorithms, and best practices.
From understanding the fundamentals to advanced techniques, this exploration will equip you with the knowledge needed to leverage predictive analytics with machine learning effectively in your organization.
Introduction to Predictive Analytics with Machine Learning
Predictive analytics involves the use of historical data, statistical algorithms, and machine learning techniques to identify the likelihood of future outcomes based on historical data patterns. On the other hand, machine learning is a subset of artificial intelligence that focuses on the development of algorithms and models that enable computers to learn from and make predictions or decisions based on data without being explicitly programmed.
The combination of predictive analytics with machine learning enhances the accuracy and efficiency of predictive models by allowing systems to automatically learn and improve from experience without human intervention. This synergy enables organizations to uncover valuable insights, identify trends, and make data-driven decisions that drive business growth and innovation.
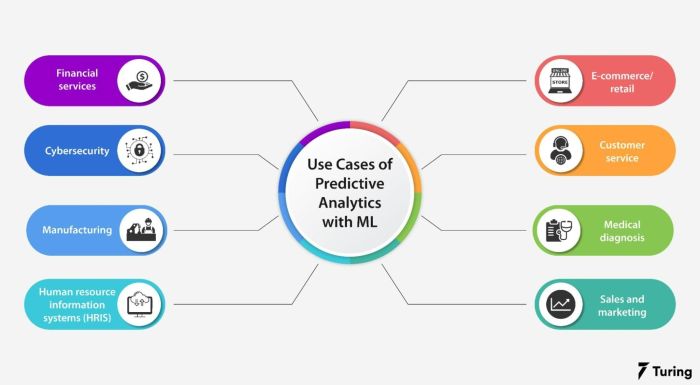
Applications of Predictive Analytics with Machine Learning
- Financial Services: Banks and financial institutions use predictive analytics with machine learning to assess credit risk, detect fraudulent activities, and personalize customer experiences.
- Healthcare: Healthcare providers leverage predictive analytics and machine learning to improve patient outcomes, optimize treatment plans, and forecast disease outbreaks.
- Retail: Retailers utilize predictive analytics with machine learning to forecast demand, optimize pricing strategies, and enhance customer segmentation.
- Marketing: Marketing professionals employ predictive analytics and machine learning to personalize marketing campaigns, predict customer behavior, and optimize advertising spend.
Machine Learning Algorithms for Predictive Analytics

Predictive analytics relies heavily on machine learning algorithms to analyze data and make accurate predictions. Different algorithms have different strengths and weaknesses, making them suitable for various types of predictive tasks. In this section, we will explore popular machine learning algorithms used in predictive analytics, compare and contrast their strengths and weaknesses, and provide real-world examples of how these algorithms have been successfully applied.
Linear Regression
Linear regression is a simple yet powerful algorithm used for predicting continuous values based on one or more input features. It works by fitting a linear relationship between the input variables and the target variable. The strengths of linear regression include its interpretability and ease of implementation. However, it may not capture complex relationships in the data and is sensitive to outliers.
Decision Trees
Decision trees are versatile algorithms that can handle both classification and regression tasks. They work by recursively splitting the data based on the features to create a tree-like structure. Decision trees are easy to interpret, handle non-linear relationships well, and are robust to outliers. However, they are prone to overfitting, especially with deep trees.
Random Forest
Random Forest is an ensemble method that combines multiple decision trees to improve prediction accuracy. It works by building a forest of trees and aggregating their predictions. Random Forest is robust to overfitting, handles high-dimensional data well, and provides feature importance scores. However, it can be computationally expensive and may not perform well with imbalanced datasets.
Support Vector Machines (SVM)
Support Vector Machines are powerful algorithms used for classification tasks. They work by finding the hyperplane that best separates the classes in the feature space. SVMs are effective in high-dimensional spaces, versatile with different kernel functions, and have regularization parameters to control overfitting. However, SVMs can be sensitive to the choice of kernel and parameters, making them challenging to tune.
Gradient Boosting Machines
Gradient Boosting Machines are ensemble methods that build a series of weak learners to create a strong learner. They work by fitting the residual errors of the previous models. Gradient Boosting Machines are robust to overfitting, handle complex relationships well, and provide feature importance. However, they can be prone to overfitting if not carefully tuned and may require more computational resources.
Data Preprocessing for Predictive Analytics
Data preprocessing is a crucial step in predictive analytics with machine learning as it involves transforming raw data into a clean, organized format that can be used to build predictive models. By preparing the data properly, we can improve the accuracy and efficiency of our predictive algorithms.
Importance of Data Preprocessing
Data preprocessing plays a vital role in predictive analytics as it helps in removing inconsistencies and errors in the data, making it more reliable for analysis. Techniques such as data cleaning, normalization, and feature engineering are essential in this process.
- Data Cleaning: This involves removing missing values, outliers, and irrelevant data from the dataset. By cleaning the data, we ensure that our predictive models are not influenced by erroneous or incomplete information.
- Normalization: Normalizing the data involves scaling the features to a standard range, which helps in preventing certain features from dominating the model. This ensures that all features are equally important in the prediction process.
- Feature Engineering: Feature engineering involves creating new features from existing ones or selecting the most relevant features for the model. This step can help in improving the model’s performance by providing more relevant information for prediction.
Examples of Data Preprocessing Benefits
Data preprocessing can significantly enhance the performance of predictive models by ensuring that the data is accurate, consistent, and relevant. For example, by cleaning the data and removing outliers, we can prevent the model from being biased by erroneous values, leading to more accurate predictions. Similarly, normalization helps in standardizing the data, making it easier for the model to interpret and learn from the features.
Overall, data preprocessing is a critical step in predictive analytics with machine learning, as it sets the foundation for building robust and accurate predictive models.
Model Evaluation and Selection

When it comes to predictive analytics with machine learning, model evaluation and selection play a crucial role in determining the accuracy and reliability of the predictions. Evaluating predictive models involves assessing their performance based on various metrics to ensure they are effective in solving the targeted business problem.
Common metrics used to assess model performance include precision, recall, and F1 score. Precision measures the accuracy of positive predictions, recall calculates the proportion of actual positives that were correctly identified, and the F1 score is the harmonic mean of precision and recall. These metrics help in understanding how well the model is performing in terms of making accurate predictions.
Strategies for Model Selection
- 1. Cross-Validation: Utilize techniques like k-fold cross-validation to assess the model’s performance on different subsets of the data.
- 2. Grid Search: Experiment with different hyperparameters to find the optimal configuration for the model.
- 3. Ensemble Methods: Combine multiple models to improve prediction accuracy and reduce overfitting.
- 4. Bias-Variance Tradeoff: Strive to find a balance between bias and variance to ensure the model generalizes well to unseen data.
Overfitting and Underfitting in Predictive Analytics

Overfitting and underfitting are common issues in predictive analytics when developing machine learning models. These phenomena occur when a model either captures noise in the training data (overfitting) or fails to capture the underlying patterns in the data (underfitting), leading to poor performance in making predictions.
Impact of Overfitting and Underfitting
Overfitting can lead to a model that performs well on the training data but fails to generalize to new, unseen data. This can result in high variance and poor predictive accuracy. On the other hand, underfitting occurs when a model is too simple and fails to capture the complexity of the data, leading to high bias and inaccurate predictions.
To prevent overfitting and underfitting in predictive analytics applications, several techniques can be employed:
Techniques to Prevent Overfitting and Underfitting, Predictive analytics with machine learning
- Regularization: Introducing penalties for complex models to prevent overfitting.
- Cross-validation: Splitting the data into multiple subsets for training and testing to evaluate model performance.
- Feature selection: Choosing relevant features to reduce model complexity and prevent overfitting.
- Ensemble methods: Combining multiple models to improve predictive accuracy and prevent overfitting.
- Early stopping: Stopping the training process before the model starts to overfit on the training data.
Feature Selection and Importance: Predictive Analytics With Machine Learning
Feature selection plays a crucial role in building effective predictive models. By identifying and selecting the most relevant features, we can improve the model’s accuracy, reduce overfitting, and enhance interpretability.
Methods for Feature Selection
- Filter Methods: These methods evaluate the relevance of features based on statistical measures, such as correlation or mutual information.
- Wrapper Methods: These methods involve selecting features based on the performance of a specific machine learning algorithm.
- Embedded Methods: These methods integrate feature selection into the model building process, such as LASSO or Ridge regression.
Feature Importance Analysis
Feature importance analysis helps us understand the impact of each feature on the predictive model’s output. By ranking features based on their importance, we can prioritize the most influential ones for better decision-making.
For example, in a predictive model for customer churn, feature importance analysis may reveal that the customer’s tenure and usage frequency are the most critical factors influencing their likelihood to churn.
In conclusion, the integration of predictive analytics with machine learning opens up a world of possibilities for businesses seeking to make data-driven decisions. By embracing these technologies, organizations can unlock valuable insights and stay ahead in today’s competitive landscape. Dive into the realm of predictive analytics with machine learning and transform the way you interpret and utilize data.
When it comes to data visualization tools, the debate between Google Data Studio vs Tableau is ongoing. While Google Data Studio offers seamless integration with other Google products, Tableau is known for its advanced features and robust capabilities. Both tools have their strengths and weaknesses, making it essential to choose the one that best fits your data visualization needs.
Understanding data warehousing architecture is crucial for businesses looking to store and manage large volumes of data efficiently. It involves designing a structure that enables data to be stored, accessed, and analyzed in a way that supports business intelligence and decision-making processes. By implementing a solid data warehousing architecture, organizations can streamline their data management and improve overall efficiency.
What is data warehousing? Data warehousing is the process of collecting, storing, and managing data from various sources to support business decision-making. It involves extracting, transforming, and loading data into a centralized repository for analysis and reporting. Data warehousing plays a crucial role in enabling organizations to gain valuable insights from their data and make informed strategic decisions.