
Kicking off with Big data mining methods, this opening paragraph is designed to captivate and engage the readers, setting the tone semrush author style that unfolds with each word.
Big data mining methods involve powerful techniques to extract valuable insights from vast amounts of data, revolutionizing decision-making processes across various industries. From classification to association rule learning, these methods play a crucial role in today’s data-driven world.
Overview of Big Data Mining Methods

Big data mining refers to the process of extracting valuable insights, patterns, and information from large datasets using various techniques and algorithms. This enables organizations to make informed decisions, improve processes, and gain a competitive edge in their respective industries.
Examples of Industries Using Big Data Mining Methods
- Finance: Banks and financial institutions use big data mining methods to detect fraudulent activities, predict market trends, and personalize customer experiences.
- Retail: Retailers utilize big data mining to analyze customer shopping patterns, optimize inventory management, and enhance marketing campaigns.
- Healthcare: Healthcare providers leverage big data mining for patient diagnosis, treatment optimization, drug discovery, and personalized medicine.
- Telecommunications: Telecom companies use big data mining to improve network performance, predict customer churn, and enhance service offerings.
Importance of Big Data Mining Methods in Today’s Data-Driven World
Big data mining methods play a crucial role in today’s data-driven world by helping organizations uncover hidden patterns and insights that can drive business growth and innovation. By analyzing large volumes of data, companies can make data-driven decisions, enhance operational efficiency, and gain a competitive advantage in a rapidly evolving market landscape.
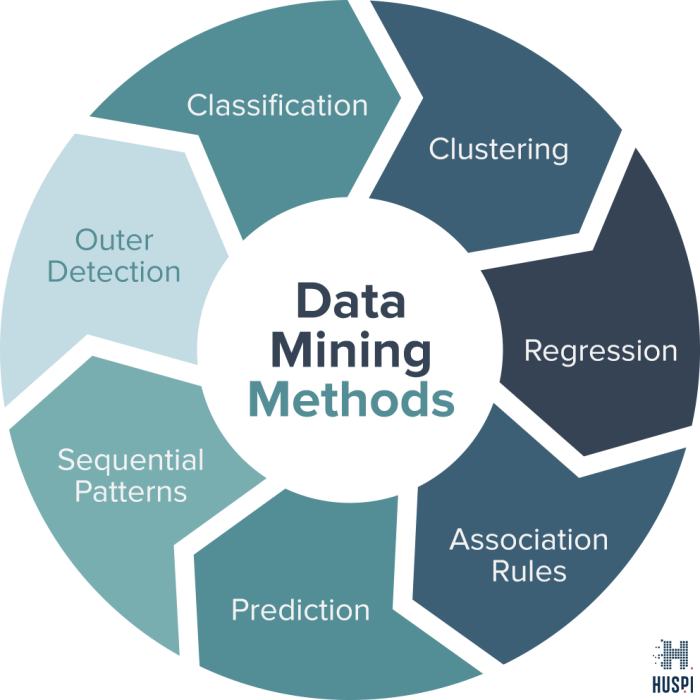
Types of Big Data Mining Methods
Big data mining methods encompass a variety of techniques used to extract valuable insights from massive datasets. These methods play a crucial role in helping organizations make data-driven decisions and gain a competitive edge in the market.
Classification
Classification is a type of big data mining method that involves categorizing data into predefined classes or labels based on their attributes. This method is often used in applications such as spam detection, sentiment analysis, and customer segmentation. By analyzing historical data and patterns, classification algorithms can predict the class of new data instances with a high level of accuracy.
Clustering
Clustering is another important big data mining method that focuses on grouping similar data points together based on their characteristics. Unlike classification, clustering does not require predefined labels and instead aims to discover natural groupings within the data. This technique is commonly used in customer segmentation, anomaly detection, and pattern recognition.
Regression
Regression is a big data mining method that involves predicting a continuous numerical value based on the relationship between input variables. This method is widely used in forecasting sales, stock prices, and other quantitative predictions. By analyzing the correlation between variables, regression algorithms can estimate the value of the target variable with a certain degree of accuracy.
Supervised vs. Unsupervised Methods
Supervised and unsupervised are two main categories of big data mining methods. Supervised learning involves training a model on labeled data, where the algorithm learns to predict the output based on input features. On the other hand, unsupervised learning deals with unlabeled data and aims to discover patterns and relationships within the data without explicit guidance. Supervised methods are used in tasks like classification and regression, while unsupervised methods are employed in clustering and anomaly detection.
Association Rule Learning
Association rule learning is a big data mining technique used to uncover interesting relationships between variables in large datasets. This method is commonly applied in market basket analysis to identify frequent itemsets and generate rules that reveal purchasing patterns. By mining association rules, businesses can optimize product placement, cross-selling strategies, and personalized recommendations to enhance customer satisfaction and drive sales.
Data Preprocessing in Big Data Mining: Big Data Mining Methods

Data preprocessing plays a crucial role in big data mining methods by improving the quality of data and ensuring more accurate results. It involves cleaning, transforming, reducing, and discretizing data before applying mining algorithms.
Cleaning
Cleaning is the process of removing noise and handling missing values in the dataset. This step is essential to ensure that the data is accurate and reliable for analysis. For example, in a dataset of customer information, cleaning would involve removing duplicate entries and filling in missing values in the age or address fields.
Transformation
Transformation involves converting the data into a suitable format for analysis. This may include normalizing the data to bring all values to a standard scale or encoding categorical variables into numerical values. For instance, transforming text data into numerical values using techniques like one-hot encoding.
Reduction
Reduction aims to decrease the size of the dataset while preserving its essential information. Techniques like principal component analysis (PCA) can be used to reduce the dimensions of the dataset without losing significant details. This helps in speeding up the processing time of the mining algorithms.
Discretization
Discretization involves converting continuous data into discrete intervals. This technique is useful when dealing with numerical data that needs to be categorized, such as age groups or income brackets. By discretizing the data, it becomes easier to analyze patterns and trends.
Data preprocessing enhances the efficiency of big data mining methods by ensuring that the data is clean, consistent, and relevant for analysis. By performing these preprocessing steps, researchers and data scientists can uncover valuable insights and make more informed decisions based on the processed data.
Machine Learning Algorithms in Big Data Mining

Machine learning algorithms play a crucial role in big data mining by enabling the extraction of valuable insights from large datasets. These algorithms are designed to analyze and interpret data patterns, making it easier for organizations to make informed decisions based on the information gathered.
Decision Trees
Decision trees are a popular machine learning algorithm used in big data mining. They work by splitting the data into smaller subsets based on certain criteria, ultimately creating a tree-like structure that helps in decision-making processes. Decision trees are particularly useful for classification and regression tasks, as they provide a clear visualization of the decision-making process.
Neural Networks, Big data mining methods
Neural networks are another powerful machine learning algorithm widely utilized in big data mining. They are inspired by the human brain’s neural network and are capable of learning complex patterns and relationships within the data. Neural networks are often used for tasks like image recognition, natural language processing, and predictive analytics.
Support Vector Machines
Support Vector Machines (SVM) are a type of supervised learning algorithm that is effective in performing classification tasks. SVM works by finding the optimal hyperplane that best separates the data points into different classes. This algorithm is particularly useful for handling high-dimensional data and is known for its accuracy in classification tasks.
Scalability Challenges
Implementing machine learning algorithms in big data mining can present scalability challenges due to the sheer volume and variety of data involved. As the size of the dataset increases, the computational resources required also grow, making it essential to optimize algorithms for efficiency. Additionally, data preprocessing and feature engineering play a crucial role in ensuring that machine learning algorithms can handle large-scale datasets effectively.
In conclusion, Big data mining methods offer a sophisticated approach to analyzing and interpreting massive datasets, empowering organizations to make informed decisions and gain competitive advantages in the digital landscape. Dive into the realm of big data mining and unlock the potential of your data today.
When it comes to data storage best practices, organizations need to implement strategies that ensure data security, accessibility, and scalability. Utilizing tools like Data storage best practices can help businesses optimize their storage infrastructure for better performance and cost-efficiency.
For those looking to analyze and visualize their data effectively, a Google Data Studio tutorial can be incredibly beneficial. This tool allows users to create interactive reports and dashboards to gain valuable insights from their data, making it a valuable asset for data-driven decision-making.