
Best machine learning algorithms set the stage for this enthralling narrative, offering readers a glimpse into a story that is rich in detail and brimming with originality from the outset. From supervised to unsupervised learning, this exploration dives deep into the world of AI algorithms.
Overview of Machine Learning Algorithms

Machine learning algorithms are a set of instructions that enable computers to learn from data and make predictions or decisions without being explicitly programmed. These algorithms play a crucial role in various fields by analyzing patterns in data and deriving valuable insights. The applications of machine learning are diverse, ranging from image and speech recognition to medical diagnosis and financial forecasting.
Types of Machine Learning Algorithms
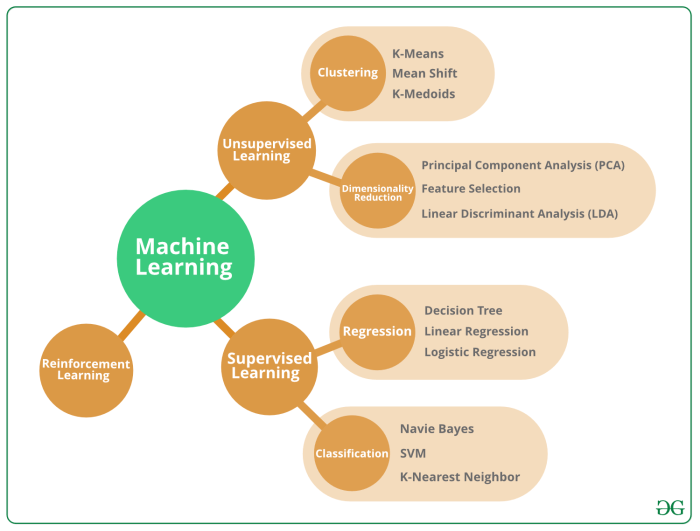
Machine learning algorithms can be broadly categorized into three main types based on the learning process: supervised learning, unsupervised learning, and reinforcement learning.
- Supervised Learning: In supervised learning, the algorithm is trained on labeled data, where the input and output are provided. The algorithm learns to map inputs to outputs, making predictions on unseen data based on the learned patterns.
- Unsupervised Learning: Unsupervised learning involves training the algorithm on unlabeled data, where the model identifies patterns and relationships without predefined output labels. This type of learning is useful for clustering and dimensionality reduction tasks.
- Reinforcement Learning: Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent receives rewards or penalties based on its actions, aiming to maximize cumulative rewards over time.
Popular Supervised Learning Algorithms
When it comes to supervised learning, there are several popular algorithms that are commonly used in the field of machine learning. These algorithms are designed to learn from labeled data and make predictions based on that information.
Linear Regression:
Linear regression is a simple yet powerful algorithm used for predicting a continuous value. It works by finding the best-fitting line that represents the relationship between the input features and the target variable. Linear regression is widely used in various fields such as finance, economics, and social sciences due to its simplicity and interpretability.
Decision Trees:
Decision trees are a versatile algorithm that can handle both regression and classification tasks. They work by splitting the data into smaller subsets based on certain criteria, ultimately creating a tree-like structure to make predictions. Decision trees are easy to understand and visualize, making them a popular choice for beginners in machine learning.
Support Vector Machines (SVM):
Support Vector Machines are a powerful algorithm for both classification and regression tasks. SVM works by finding the hyperplane that best separates the different classes in the data. It is known for its ability to handle high-dimensional data and complex decision boundaries. SVM is widely used in applications like image recognition, text categorization, and bioinformatics.
Comparison of Popular Supervised Learning Algorithms, Best machine learning algorithms
When it comes to comparing the performance of these popular supervised learning algorithms, several factors need to be considered:
– Accuracy: Decision trees and Support Vector Machines (SVM) are known to perform well in terms of accuracy, especially in complex datasets. Linear regression, on the other hand, may struggle with non-linear relationships between features and the target variable.
– Training Time: Linear regression is known for its fast training times since it is a simple algorithm. Decision trees can be prone to overfitting, which may increase training time. SVM, while powerful, can be computationally expensive for large datasets.
– Interpretability: Linear regression and decision trees are highly interpretable algorithms, making it easy to understand how they make predictions. SVM, on the other hand, can be more challenging to interpret due to the complex decision boundaries it creates.
In conclusion, the choice of algorithm depends on the specific characteristics of the dataset and the problem at hand. Each of these popular supervised learning algorithms has its strengths and weaknesses, making them suitable for different scenarios in machine learning applications.
Key Unsupervised Learning Algorithms

Unsupervised learning algorithms are used to uncover patterns and relationships within data without the need for labeled outputs. This allows for exploration and discovery of hidden structures in the data. Some of the key unsupervised learning algorithms include K-means clustering, Hierarchical clustering, and Principal Component Analysis (PCA). Let’s delve into each of these algorithms and their applications in clustering and dimensionality reduction.
K-means Clustering
K-means clustering is a popular unsupervised learning algorithm used for partitioning a dataset into K clusters based on similarity measures. The algorithm iteratively assigns data points to the nearest cluster centroid and updates the centroid until convergence is reached. K-means clustering is widely used in customer segmentation, anomaly detection, and image compression.
Hierarchical Clustering
Hierarchical clustering is another unsupervised learning algorithm that builds a tree of clusters by either merging or splitting existing clusters based on similarity measures. This algorithm does not require the number of clusters to be specified beforehand, making it suitable for exploratory data analysis and visualization. Hierarchical clustering is commonly used in biological taxonomy, social network analysis, and market segmentation.
Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is a dimensionality reduction technique that transforms high-dimensional data into a lower-dimensional space while preserving the variance in the data. PCA identifies the principal components that explain the most variance in the data and projects the data onto these components. PCA is widely applied in image processing, finance, and genetics for feature extraction and data visualization.
Advanced Machine Learning Techniques

Machine learning has evolved to encompass a wide range of algorithms and techniques, with advanced methods like Random Forest, Gradient Boosting, and Neural Networks taking center stage. These techniques offer enhanced capabilities for handling complex datasets and improving predictive accuracy.
Random Forest
Random Forest is a versatile ensemble learning algorithm that combines multiple decision trees to create a more robust and accurate model. By aggregating the predictions of individual trees, Random Forest can mitigate overfitting and enhance generalization, making it well-suited for a variety of tasks, from classification to regression.
Gradient Boosting
Gradient Boosting is another ensemble learning technique that sequentially builds a series of weak learners to create a strong predictive model. By optimizing a loss function at each step, Gradient Boosting can improve the model’s performance over time, making it particularly effective for complex datasets with non-linear relationships.
Neural Networks
Neural Networks are a class of deep learning algorithms inspired by the human brain’s neural structure. With multiple layers of interconnected nodes (neurons), Neural Networks can learn complex patterns and relationships in data, making them well-suited for tasks like image recognition, natural language processing, and more.
Trade-offs and Considerations: Best Machine Learning Algorithms
While advanced machine learning techniques offer significant benefits in terms of predictive accuracy and model performance, they also come with trade-offs compared to traditional algorithms. Advanced techniques like Random Forest and Gradient Boosting can be computationally intensive and require more data for training, making them less suitable for simple or smaller datasets. Additionally, Neural Networks can be challenging to interpret and prone to overfitting if not properly regularized.
As we wrap up our journey through the realm of machine learning algorithms, one thing is certain – the power of AI to transform industries and drive innovation is undeniable. With the right algorithms at our disposal, the possibilities are endless.
When it comes to data storage best practices , it is essential to prioritize security, redundancy, and scalability. Implementing proper backup procedures and encryption methods can help safeguard sensitive information from cyber threats.
Businesses can benefit greatly from utilizing data warehousing solutions. By centralizing data storage and streamlining access for analytics purposes, organizations can make more informed decisions based on accurate and up-to-date information.
KNIME for data science is a powerful tool that offers a wide range of functionalities for data analysis, visualization, and modeling. Its user-friendly interface and extensive library of plugins make it a popular choice among data scientists and researchers.