
Machine learning in data analysis opens a door to the world of algorithms that unravel insights from data, setting the stage for transformative analysis. Dive into the realm where data meets intelligence.
Exploring the various facets of machine learning in data analysis, we uncover the essence of extracting valuable insights and patterns from complex datasets.
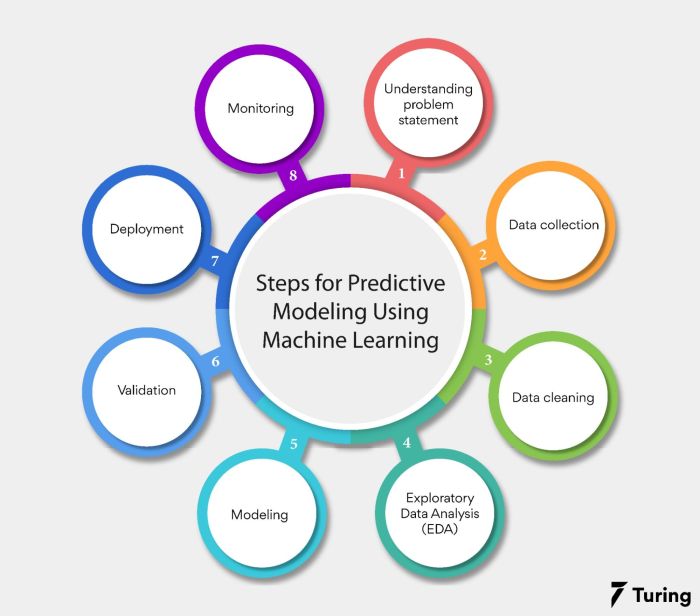
Introduction to Machine Learning in Data Analysis

Machine learning refers to the use of algorithms and statistical models to enable computer systems to learn from data and make decisions without being explicitly programmed. In the context of data analysis, machine learning plays a crucial role in extracting valuable insights and patterns from large datasets that may be too complex for traditional analytical techniques to handle.
Importance of Machine Learning in Data Analysis
Machine learning algorithms are essential for processing and analyzing vast amounts of data quickly and efficiently. They can identify trends, patterns, and anomalies that humans may not easily detect, leading to more informed decision-making in various industries. By automating the process of data analysis, machine learning helps businesses gain a competitive edge by uncovering hidden insights that drive innovation and growth.
- Machine learning algorithms can analyze customer behavior to predict future trends and personalize marketing strategies accordingly.
- In healthcare, machine learning can assist in diagnosing diseases, predicting patient outcomes, and optimizing treatment plans based on historical data.
- Financial institutions use machine learning to detect fraudulent activities, manage risks, and make data-driven investment decisions.
Types of Machine Learning Algorithms for Data Analysis: Machine Learning In Data Analysis
Machine learning algorithms play a crucial role in data analysis by enabling computers to learn from data and make predictions or decisions. There are several types of machine learning algorithms commonly used in data analysis, including supervised, unsupervised, and reinforcement learning.
Supervised Learning Algorithms
Supervised learning algorithms are trained on labeled data, where the input data is paired with the correct output. These algorithms learn from the labeled data to make predictions on new, unseen data. Examples of supervised learning algorithms include linear regression, logistic regression, support vector machines, decision trees, and random forests. Use cases for supervised learning algorithms in data analysis include predicting customer churn, sentiment analysis, image recognition, and spam detection.
Unsupervised Learning Algorithms
Unsupervised learning algorithms are used on unlabeled data to identify patterns or relationships within the data. These algorithms do not have predefined outputs, and their goal is to find hidden structures in the data. Examples of unsupervised learning algorithms include clustering algorithms like K-means, hierarchical clustering, and dimensionality reduction techniques like principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE). Use cases for unsupervised learning algorithms in data analysis include customer segmentation, anomaly detection, and market basket analysis.
Reinforcement Learning Algorithms, Machine learning in data analysis
Reinforcement learning algorithms learn through trial and error by interacting with an environment and receiving feedback in the form of rewards or penalties. These algorithms aim to maximize cumulative rewards over time by taking actions that lead to positive outcomes. Examples of reinforcement learning algorithms include Q-learning, deep Q-networks, and policy gradients. Use cases for reinforcement learning algorithms in data analysis include game playing, robotics, and optimizing resource allocation.
Data Preprocessing Techniques for Machine Learning in Data Analysis

Data preprocessing is a crucial step in machine learning for effective data analysis. It involves transforming raw data into a clean and structured format that is suitable for training machine learning models. By preprocessing the data, we can improve the accuracy and efficiency of the models, leading to better insights and predictions.
Normalization
Normalization is a common data preprocessing technique used to scale the numerical features of the dataset to a standard range. This ensures that all features have the same scale, preventing any particular feature from dominating the model. By normalizing the data, we can improve the performance of machine learning algorithms such as K-Nearest Neighbors and Support Vector Machines.
Encoding
Encoding is another important preprocessing technique used to convert categorical variables into numerical values. This is necessary because many machine learning algorithms require numerical input. One common method of encoding is one-hot encoding, where each category is represented by a binary value. By encoding categorical variables, we can include them in our models and make better predictions.
Missing Value Imputation
Missing value imputation is the process of filling in missing data points in the dataset. Missing values can cause errors in machine learning algorithms, leading to inaccurate results. Common methods of imputation include mean imputation, median imputation, and using predictive models to fill in missing values. By addressing missing data, we can ensure that our models are robust and reliable.
Overall, data preprocessing plays a crucial role in the success of machine learning models in data analysis. By applying techniques such as normalization, encoding, and missing value imputation, we can create clean and reliable datasets that lead to more accurate predictions and valuable insights.
Evaluation Metrics for Machine Learning Models in Data Analysis

Evaluation metrics play a crucial role in assessing the performance of machine learning models. These metrics help in understanding how well a model is performing and making informed decisions about its effectiveness.
Key Evaluation Metrics
- Accuracy: Accuracy measures the ratio of correctly predicted instances to the total number of instances in the dataset. It is a simple and intuitive metric but may not be suitable for imbalanced datasets.
- Precision: Precision calculates the ratio of correctly predicted positive observations to the total predicted positive observations. It focuses on the exactness of the model’s predictions.
- Recall: Recall, also known as sensitivity, measures the ratio of correctly predicted positive observations to the all actual positive observations in the dataset. It helps in understanding how well the model captures all positive instances.
- F1 Score: The F1 score is the harmonic mean of precision and recall. It provides a balance between precision and recall, making it a useful metric for imbalanced datasets.
- ROC-AUC: Receiver Operating Characteristic – Area Under the Curve (ROC-AUC) is a performance measurement for classification problems. It represents the likelihood that the model will rank a randomly chosen positive instance higher than a randomly chosen negative instance.
Varying Evaluation Metrics
The choice of evaluation metrics can vary based on the nature of the data and the data analysis task at hand. For example, in a binary classification problem where false positives are more critical than false negatives, precision may be a more relevant metric. On the other hand, in a scenario where both false positives and false negatives need to be minimized equally, the F1 score could be a better evaluation metric. Understanding the context and requirements of the problem is essential in selecting the most appropriate evaluation metrics for machine learning models.
In conclusion, the journey through machine learning in data analysis showcases the fusion of technology and data, offering a glimpse into the future of analytics. Embrace the power of algorithms and unleash the true potential of your data.
Looking for inspiration for your Tableau dashboard? Check out these amazing Tableau dashboard examples that showcase the power of data visualization. From sales performance to customer analytics, these examples cover a wide range of industries and use cases.
Are you considering Microsoft Azure Synapse Analytics for your data processing needs? Learn more about the capabilities and benefits of Microsoft Azure Synapse Analytics in handling big data workloads and streamlining your analytics process. Stay ahead of the competition with this powerful tool.
Setting up a data warehouse can be a daunting task, but with the right guidance, you can streamline the process. Check out this comprehensive guide on how to set up a data warehouse and ensure that your data is organized and accessible for all your analytical needs. Start building a solid foundation for your data strategy today.