
Data mining process steps: With Data mining process steps at the forefront, this paragraph opens a window to an amazing start and intrigue, inviting readers to embark on a storytelling semrush author style filled with unexpected twists and insights.
The data mining process is like a treasure hunt where valuable insights are waiting to be discovered. By following specific steps, businesses can unlock hidden patterns and make informed decisions based on data analysis. Let’s delve into the key steps involved in the data mining process to reveal the secrets of extracting valuable insights.
Introduction to Data Mining: Data Mining Process Steps
Data mining is the process of extracting valuable information from large datasets to uncover patterns, trends, and insights that can help businesses make informed decisions. In today’s digital age, data mining plays a crucial role in various industries by enabling organizations to analyze vast amounts of data quickly and efficiently.
Importance of Data Mining
Data mining is essential for businesses as it allows them to gain a competitive edge by identifying opportunities for growth, improving operational efficiency, and enhancing customer satisfaction. By analyzing customer behavior, market trends, and operational data, companies can make data-driven decisions that drive business success.
- Data mining helps businesses identify customer preferences and tailor marketing strategies to meet their needs effectively.
- It enables companies to forecast demand, optimize inventory levels, and improve supply chain management.
- By analyzing operational data, organizations can identify inefficiencies, streamline processes, and reduce costs.
Examples of Industries Benefiting from Data Mining
- Retail: Retailers use data mining to analyze customer purchase history, predict trends, and personalize marketing campaigns to increase sales.
- Healthcare: Healthcare providers utilize data mining to improve patient outcomes, identify high-risk patients, and optimize treatment plans.
- Finance: Financial institutions leverage data mining to detect fraudulent activities, assess credit risk, and personalize investment recommendations for clients.
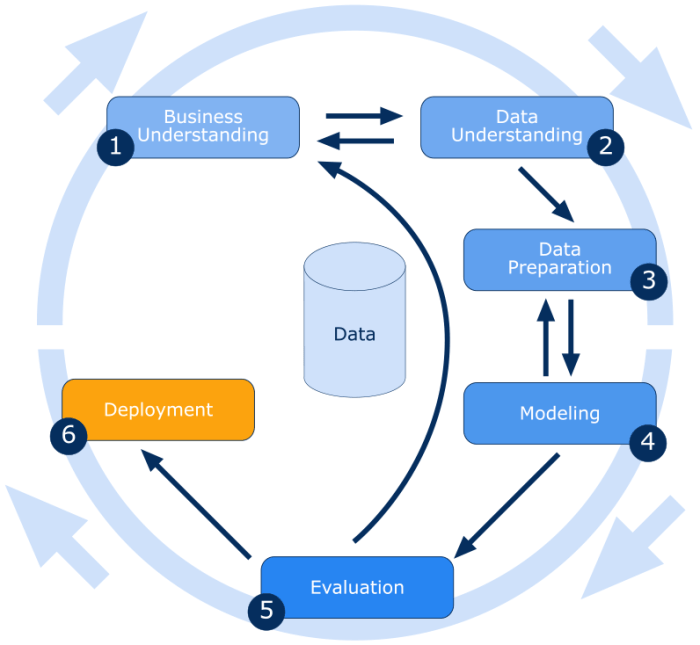
Data Mining Process Overview
In data mining, the process involves various key steps that are essential in extracting valuable insights from large datasets. Each step plays a crucial role in uncovering patterns, trends, and relationships within the data, ultimately leading to actionable insights for decision-making.
Key Steps in the Data Mining Process
- Data Cleaning: This step involves removing noise, handling missing values, and ensuring data consistency to prepare the dataset for analysis.
- Exploratory Data Analysis: Here, the data is visually explored to understand its distribution, relationships, and identify potential patterns.
- Feature Selection: In this step, relevant features are selected to build a predictive model and improve its performance.
- Model Building: Data mining algorithms are applied to the dataset to build predictive models based on the selected features.
- Evaluation: The models are evaluated using performance metrics to assess their accuracy and effectiveness in predicting outcomes.
- Deployment: Finally, the best-performing model is deployed in a real-world setting to make predictions or recommendations.
Role of Each Step in Extracting Valuable Insights
- Data Cleaning: Ensures high data quality for accurate analysis and prevents biased results.
- Exploratory Data Analysis: Helps in understanding the data and identifying patterns that can guide further analysis.
- Feature Selection: Improves model performance by focusing on relevant features and reducing complexity.
- Model Building: Utilizes algorithms to uncover hidden patterns and relationships within the data for predictive insights.
- Evaluation: Assesses the model’s accuracy and reliability in making predictions to ensure its effectiveness.
- Deployment: Translates the insights gained from the model into practical solutions for decision-making and problem-solving.
Comparison with Traditional Data Analysis Methods
Data mining differs from traditional data analysis methods in terms of its focus on discovering patterns and relationships in large datasets. While traditional methods may involve descriptive statistics and hypothesis testing, data mining leverages advanced algorithms to uncover hidden insights that may not be apparent through manual analysis. Additionally, data mining emphasizes predictive modeling and machine learning techniques to extract valuable information for decision-making, making it a powerful tool for analyzing complex datasets.
Data Collection Phase

The data collection phase is a crucial step in the data mining process as it involves gathering the necessary information to analyze and extract valuable insights. Without high-quality data, the effectiveness of data mining efforts can be compromised.
Strategies for Collecting Relevant Data, Data mining process steps
- Utilizing web scraping tools to extract data from websites and online sources.
- Collaborating with third-party data providers to acquire specific datasets.
- Implementing surveys and questionnaires to collect targeted information directly from users.
- Accessing internal databases within organizations to retrieve relevant data.
Examples of Data Sources
- Social media platforms such as Twitter, Facebook, and Instagram.
- E-commerce websites like Amazon, eBay, and Etsy.
- Government databases containing demographic and economic information.
- Healthcare records from hospitals and medical facilities.
Importance of High-Quality Data
High-quality data is essential for accurate and reliable results in data mining processes. It ensures that the insights generated are meaningful and actionable, leading to informed decision-making. Without high-quality data, the analysis may be skewed, leading to erroneous conclusions and ineffective strategies.
When it comes to setting up a data warehouse, it’s crucial to follow a strategic approach. One of the key steps is to clearly define the objectives and scope of the warehouse. You can learn more about how to set up a data warehouse to ensure it aligns with your business goals and requirements.
Data Preprocessing

Data preprocessing is a crucial step in the data mining process that involves cleaning, transforming, and preparing raw data before it can be used for analysis. This step is essential to ensure that the data is accurate, consistent, and relevant for building data mining models.
Common Techniques Used in Data Preprocessing
- Handling missing values: Techniques such as mean imputation, mode imputation, or using predictive models to fill in missing values.
- Data transformation: Normalizing or standardizing data to ensure all variables are on the same scale.
- Removing duplicates: Identifying and eliminating duplicate records to prevent bias in the analysis.
- Feature selection: Selecting the most relevant features to improve model performance and reduce overfitting.
- Outlier detection: Identifying and handling outliers that can skew the results of data mining models.
Importance of Data Preprocessing in Improving Model Accuracy
Data preprocessing plays a critical role in improving the accuracy of data mining models by ensuring that the data is clean, consistent, and relevant. By handling missing values, transforming data, removing duplicates, and selecting relevant features, data preprocessing helps to create a more robust and accurate model. Additionally, outlier detection ensures that the model is not influenced by anomalies in the data, leading to more reliable predictions and insights.
Exploratory Data Analysis (EDA)
Exploratory Data Analysis (EDA) is a crucial step in the data mining process that involves analyzing and visualizing data to uncover patterns, trends, and relationships. EDA helps in understanding the underlying structure of the data before applying more complex data mining techniques.
Tools and Methods Used in EDA
- Descriptive Statistics: Utilizing measures such as mean, median, mode, standard deviation, and variance to summarize the data.
- Data Visualization: Creating plots like histograms, scatter plots, box plots, and heatmaps to visualize the distribution and relationships within the data.
- Correlation Analysis: Examining the strength and direction of relationships between variables using correlation coefficients.
- Cluster Analysis: Grouping similar data points together to identify patterns and clusters within the data.
- Principal Component Analysis (PCA): Reducing the dimensionality of the data to identify the most significant features.
Role of EDA in Data Mining
- Identifying Outliers: EDA helps in detecting anomalies or outliers in the data that can skew the analysis results.
- Feature Selection: By exploring the data, EDA aids in selecting relevant features that are important for building predictive models.
- Pattern Recognition: EDA uncovers hidden patterns and relationships within the data that can lead to actionable insights and decisions.
- Data Preparation: EDA assists in understanding the data distribution and quality, guiding the preprocessing steps for data cleaning and transformation.
Model Building and Evaluation

Model building is a crucial step in the data mining process where various algorithms are applied to the preprocessed data to create predictive models. These models help in extracting valuable insights and making informed decisions.
Building Data Mining Models
- Selecting the appropriate algorithm based on the type of data and the problem to be solved.
- Splitting the data into training and testing sets to evaluate the model’s performance.
- Tuning the model parameters to improve its accuracy and efficiency.
- Training the model on the training data to learn the patterns and relationships within the data.
Criteria for Evaluating Model Performance
- Accuracy: Measures how often the model’s predictions are correct.
- Precision: Indicates the percentage of correctly predicted positive instances.
- Recall: Measures the percentage of actual positive instances that were correctly predicted.
- F1 Score: Combines precision and recall into a single metric to assess the model’s overall performance.
Importance of Model Evaluation
Model evaluation is crucial in the data mining process as it helps in assessing the effectiveness and reliability of the predictive models. By evaluating the models, data scientists can identify the strengths and weaknesses of the models, fine-tune them for better performance, and ensure that they provide accurate predictions for decision-making.
Interpretation and Deployment
Data mining models generate valuable insights from complex datasets, but the real value lies in interpreting these results and deploying them effectively in real-world scenarios. This involves understanding the implications of the findings and implementing them to drive informed decision-making.
Interpreting Data Mining Results
Interpreting data mining results is crucial for extracting actionable insights from the models. This process involves analyzing the output to understand the patterns, trends, and relationships uncovered by the algorithms. It is essential to validate the results and ensure they align with the business objectives. Visualization tools, such as charts and graphs, can aid in interpreting the findings and communicating them effectively to stakeholders.
Strategies for Deploying Data Mining Models
Deploying data mining models in real-world scenarios requires careful planning and execution. One strategy is to integrate the models into existing systems or workflows to automate decision-making processes. Another approach is to develop user-friendly interfaces that allow non-technical users to interact with the models and access the insights they provide. Regular training and support for end-users are essential for successful deployment.
Significance of Continuous Monitoring and Updating
Continuous monitoring and updating of deployed data mining models are critical for ensuring their relevance and accuracy over time. As new data becomes available or business requirements change, the models need to be re-evaluated and updated accordingly. This ongoing maintenance helps prevent model drift and ensures that the insights generated remain valuable for decision-making.
In conclusion, mastering the data mining process steps is essential for businesses looking to gain a competitive edge through data-driven decision-making. By understanding the key phases and techniques involved, organizations can uncover hidden trends and patterns that can lead to actionable insights. Embrace the power of data mining process steps and take your data analysis to the next level.
Once your data warehouse is up and running, the next step is to utilize effective data analysis techniques. These techniques help in extracting valuable insights from your data. By mastering data analysis techniques , you can make informed decisions and drive business growth.
Data visualization tools play a critical role in presenting complex data in a clear and understandable manner. By utilizing data visualization tools , you can create insightful dashboards and reports that facilitate data-driven decision-making within your organization.