
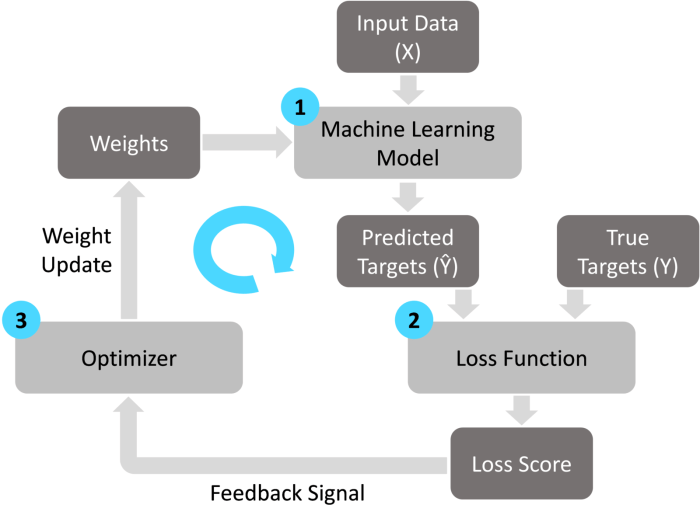
Machine learning model training sets the stage for optimizing model performance, diving deep into the realm of algorithms and techniques that shape the future of AI.
As we unravel the intricacies of model training, a world of possibilities opens up, showcasing the power of data-driven decision-making and innovation.
Overview of Machine Learning Model Training

Machine learning model training is the process of teaching a machine learning algorithm to recognize patterns and make predictions based on data. This crucial step in the machine learning pipeline involves feeding the algorithm with labeled data to adjust its parameters and optimize its performance.
Importance of Data Preparation
Data preparation is essential before initiating model training as the quality of the data directly impacts the accuracy and effectiveness of the model. It involves cleaning, transforming, and organizing the data to ensure that it is in a format suitable for the algorithm to learn from. Without proper data preparation, the model may be trained on noisy or incomplete data, leading to inaccurate predictions.
- Cleaning the data by removing duplicates, handling missing values, and correcting errors ensures that the model learns from accurate and reliable information.
- Transforming the data through feature engineering, normalization, or encoding categorical variables helps the algorithm better understand the underlying patterns in the data.
- Organizing the data into training and testing sets allows for evaluating the model’s performance and generalization to unseen data.
Techniques for Model Training

Machine learning models are trained using various techniques to optimize performance and accuracy. Here, we will discuss popular algorithms, hyperparameter tuning, and the differences between supervised and unsupervised learning methods.
Popular Algorithms for Model Training
- Linear Regression
- Logistic Regression
- Decision Trees
- Random Forest
- Support Vector Machines
- K-Nearest Neighbors
- Neural Networks
Hyperparameter Tuning
Hyperparameter tuning involves adjusting the parameters of a machine learning model to optimize its performance. This process helps find the best combination of hyperparameters that result in the most accurate predictions. It plays a crucial role in improving the model’s efficiency and accuracy.
Supervised vs. Unsupervised Learning
- Supervised Learning: In supervised learning, the model is trained using labeled data, where the algorithm learns from input-output pairs. The goal is to predict the output based on new input data. Common supervised learning algorithms include regression and classification models.
- Unsupervised Learning: Unsupervised learning involves training the model on unlabeled data, where the algorithm tries to find patterns or structure in the data. Clustering and dimensionality reduction are common unsupervised learning techniques.
Data Splitting for Training

When training a machine learning model, it is crucial to split the available data into two sets: a training set and a testing set. This division allows the model to learn from the training data and then evaluate its performance on unseen data to assess its generalization capabilities.
Significance of Cross-Validation Techniques
Cross-validation techniques are essential during model training as they help in evaluating the model’s performance and generalizability. By splitting the data into multiple subsets and training the model on different combinations of these subsets, cross-validation provides a more robust assessment of the model’s effectiveness.
- One common cross-validation technique is k-fold cross-validation, where the data is divided into k subsets. The model is then trained on k-1 subsets and tested on the remaining subset, repeating this process k times to ensure each subset is used for testing.
- Another technique is stratified k-fold cross-validation, which ensures that each fold contains a proportional representation of the different classes present in the data, particularly useful for imbalanced datasets.
Common Data Splitting Ratios
- A common ratio for splitting data is 80% for training and 20% for testing. This ensures that the model has sufficient data to learn from while still having unseen data for evaluation.
- In some cases, a 70-30 split may be used, especially when dealing with limited data or when a higher proportion of data is needed for training.
Feature Engineering in Model Training: Machine Learning Model Training
Feature engineering plays a crucial role in enhancing the performance of machine learning models by transforming raw data into a format that is better suited for model training. By creating new features or modifying existing ones, feature engineering allows models to extract relevant patterns and relationships from the data more effectively.
Techniques for Feature Engineering
- One-Hot Encoding: One-hot encoding is a technique used to convert categorical variables into a numerical format. Each category is represented as a binary vector, where only one element is “hot” (1) while the others are “cold” (0). This helps the model understand the categorical data and prevents it from assuming any ordinal relationship between categories.
- Normalization: Normalization is the process of scaling numerical features to a standard range, typically between 0 and 1. This ensures that all features contribute equally to the model training process, preventing certain features from dominating others due to their scale.
- Feature Scaling: Feature scaling involves standardizing the range of independent variables or features of data. This is important for algorithms that are sensitive to the scale of input features, such as Support Vector Machines and K-Nearest Neighbors. Common scaling methods include Min-Max scaling and Z-score normalization.
Impact of Feature Engineering on Model Accuracy
Feature engineering can significantly impact the accuracy of machine learning models by providing valuable insights and patterns to the algorithms. For example, in a classification task, creating new features that capture the interactions between existing variables can help the model better distinguish between classes. Similarly, normalizing features can prevent bias towards certain attributes, leading to a more balanced and accurate model.
Model Evaluation Metrics
When training machine learning models, it is crucial to evaluate their performance using specific metrics. These evaluation metrics help us understand how well the model is performing and identify areas for improvement.
Accuracy
Accuracy is a commonly used metric that measures the proportion of correctly classified instances out of the total instances. It is a simple and intuitive metric, but it may not be suitable for imbalanced datasets where one class dominates the others.
Precision
Precision measures the proportion of true positive predictions out of all positive predictions made by the model. It is essential in scenarios where false positives are costly or must be minimized.
Recall
Recall, also known as sensitivity, measures the proportion of true positive predictions out of all actual positive instances in the dataset. It is crucial when false negatives need to be minimized, such as in medical diagnoses.
F1 Score, Machine learning model training
The F1 score is the harmonic mean of precision and recall, providing a balance between the two metrics. It is useful when there is a need to consider both precision and recall equally.
In conclusion, mastering the art of model optimization through machine learning model training unlocks a realm of endless opportunities, propelling us towards a future where AI-driven solutions revolutionize the way we interact with technology.
Setting up a data warehouse is crucial for businesses looking to centralize and analyze large amounts of data. By following the steps outlined in this guide on How to set up a data warehouse , organizations can improve their data management processes and make more informed decisions.
Data storytelling with Power BI is a powerful way to communicate insights from data to stakeholders. With the help of tools like Power BI, businesses can create compelling visualizations and narratives. Learn more about how to leverage Power BI for data storytelling in this article on Data storytelling with Power BI.
Enterprises require robust data storage solutions to manage their growing volumes of information. Explore different options and considerations for data storage in this comprehensive guide on Data storage solutions for enterprises. Implementing the right storage solution can enhance efficiency and scalability for businesses.