
Data warehousing architecture sets the stage for this enthralling narrative, offering readers a glimpse into a story that is rich in detail and brimming with originality from the outset. As we delve into the components, types, design principles, and ETL processes, the intricate world of data management comes to life in a captivating manner.
Overview of Data Warehousing Architecture
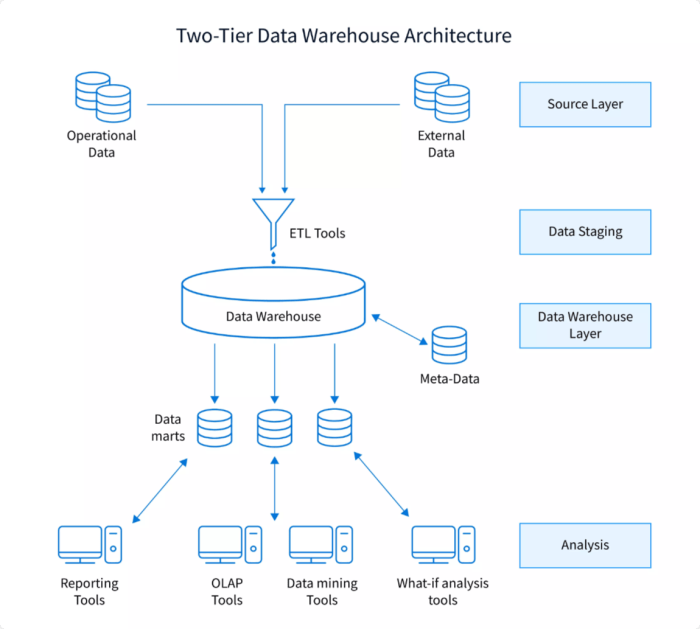
Data warehousing architecture consists of various components that work together to support the storage, retrieval, and analysis of large volumes of data. These components include:
Components of Data Warehousing Architecture
- Data Sources: These are systems or applications that generate data, which is then extracted and loaded into the data warehouse.
- ETL (Extract, Transform, Load): This process involves extracting data from source systems, transforming it into a format suitable for analysis, and loading it into the data warehouse.
- Data Warehouse Database: This is where the data is stored in a structured manner, optimized for reporting and analysis.
- OLAP (Online Analytical Processing) Engine: This component allows users to perform complex, multidimensional analysis on the data stored in the warehouse.
- Metadata Repository: This stores information about the data in the warehouse, including data definitions, relationships, and usage.
- Query and Reporting Tools: These tools enable users to access and analyze data stored in the warehouse through queries and reports.
The purpose of data warehousing architecture is to provide a centralized repository of data that is optimized for analysis and reporting. By consolidating data from multiple sources into a single location, organizations can gain valuable insights and make informed decisions based on data-driven evidence.
Importance of Data Warehousing Architecture in Modern Business Operations
Data warehousing architecture plays a crucial role in modern business operations by enabling organizations to:
- Gain a comprehensive view of their data: By integrating data from various sources, organizations can get a holistic view of their operations and performance.
- Improve decision-making: Access to timely and accurate data allows decision-makers to make informed choices that drive business success.
- Enhance data quality: Data warehousing architecture helps ensure data consistency, integrity, and quality, leading to more reliable insights and analysis.
- Increase operational efficiency: With a centralized data repository, organizations can streamline data management processes and improve overall efficiency.
Types of Data Warehousing Architectures
In the realm of data warehousing, different architectures play a crucial role in shaping how data is stored, processed, and accessed. Let’s delve into the various types of data warehousing architectures, namely single-tier, two-tier, and three-tier, and explore their unique characteristics.

Single-Tier Data Warehousing Architecture
Single-tier data warehousing architecture involves storing data in a single database server. This simplistic approach allows for easy management and quick access to data. However, it may lead to performance issues when dealing with large datasets or complex queries. An example of a real-world application of single-tier architecture is a small retail business using a single database server to store sales data.
Two-Tier Data Warehousing Architecture
Two-tier data warehousing architecture comprises two layers: the client layer for data access and the server layer for data storage. This architecture offers better scalability and performance compared to single-tier architecture. However, it may still face challenges with data integration and maintenance. An example of two-tier architecture is a medium-sized enterprise using separate servers for data storage and data access.
Three-Tier Data Warehousing Architecture
Three-tier data warehousing architecture involves three layers: the client layer for data visualization, the application layer for data processing, and the server layer for data storage. This architecture provides enhanced scalability, flexibility, and security. However, it requires more resources and expertise for maintenance. A real-world example of three-tier architecture is a large corporation using distinct servers for data presentation, data processing, and data storage.
Each type of data warehousing architecture has its own set of advantages and disadvantages, catering to different organizational needs and complexities.
Data Warehouse Design Principles

Data warehouse design principles are essential for creating a robust and efficient data warehousing architecture. These principles govern the structure and organization of data within the data warehouse, ensuring that it meets the needs of the users and the business. Two key design principles that play a crucial role in data warehousing architecture are normalization and denormalization, as well as data modeling.
Normalization and Denormalization
Normalization and denormalization are two opposing techniques used in database design, and they also play a significant role in data warehouse design.
- Normalization: This process involves organizing data in a relational database to reduce redundancy and improve data integrity. By breaking down data into smaller tables and eliminating duplicate information, normalization helps in maintaining data consistency. However, in a data warehouse, full normalization may not always be the best approach as it can lead to complex queries and performance issues.
- Denormalization: In contrast, denormalization involves combining tables to reduce the number of joins required to retrieve data. This technique is often used in data warehousing to improve query performance and simplify data retrieval. By storing redundant data, denormalization can speed up analytical queries and reporting processes.
Data Modeling in Data Warehousing Architecture
Data modeling is a crucial aspect of data warehousing architecture, as it helps in defining the structure of the data warehouse and how data is organized and stored.
- Conceptual Data Model: This high-level view of the data warehouse defines the entities and their relationships, providing a blueprint for the overall design.
- Logical Data Model: This model translates the conceptual data model into a more detailed representation, including tables, columns, and relationships. It serves as the basis for creating the physical data model.
- Physical Data Model: This model specifies how the data is actually stored in the data warehouse, including indexing, partitioning, and optimization strategies. It defines the implementation details of the data warehouse design.
ETL Processes in Data Warehousing Architecture

Extract, Transform, Load (ETL) processes play a crucial role in data warehousing architecture by facilitating the extraction of data from various sources, transforming it into a consistent format, and loading it into the data warehouse for analysis and reporting.
Significance of ETL Processes
ETL processes are essential for ensuring that data is cleansed, integrated, and structured appropriately before being stored in the data warehouse. This helps maintain data quality, consistency, and accuracy, enabling organizations to make informed decisions based on reliable information.
- Extract: Involves extracting data from multiple sources such as databases, applications, and flat files.
- Transform: Includes cleaning, filtering, aggregating, and transforming the extracted data to make it consistent and compatible with the data warehouse schema.
- Load: Involves loading the transformed data into the data warehouse, ensuring that it is organized and accessible for analysis and reporting.
Challenges Associated with ETL Processes
Implementing ETL processes in data warehousing architecture can pose several challenges, including:
- Volume and Variety of Data: Dealing with large volumes of data from diverse sources can be complex and time-consuming.
- Data Quality Issues: Ensuring data accuracy, consistency, and integrity throughout the ETL process can be challenging.
- Performance Optimization: Optimizing ETL processes to minimize processing time and maximize efficiency is crucial for timely data delivery.
Best Practices for Efficient ETL Processes, Data warehousing architecture
To overcome the challenges associated with ETL processes and ensure their efficiency, organizations can follow these best practices:
- Use Incremental Loading: Implement incremental loading techniques to only process and load new or updated data, reducing processing time and resource utilization.
- Data Profiling: Conduct data profiling to analyze and understand the quality, structure, and relationships within the data, enabling better transformation and cleansing strategies.
- Error Handling: Implement robust error handling mechanisms to identify and rectify data issues during the ETL process, ensuring data integrity and reliability.
In conclusion, data warehousing architecture serves as a cornerstone in modern business operations, providing a structured framework for efficient data handling. By understanding the components, types, design principles, and ETL processes involved, organizations can optimize their data management strategies and drive success in the digital age.
When it comes to revolutionizing data management, Snowflake Data Warehouse stands out as a game-changer in the industry. Its unique architecture and cloud-based approach have redefined how organizations handle their data, offering scalability and flexibility like never before.
For those looking for a comprehensive guide to data warehousing and analytics, the Amazon Redshift tutorial is a must-read resource. With its powerful features and capabilities, Amazon Redshift empowers businesses to make informed decisions based on real-time data insights.
Optimizing business intelligence is crucial in today’s competitive landscape, and Enterprise Data Warehousing plays a vital role in this process. By centralizing and organizing data, businesses can extract valuable insights to drive growth and success.